Interaktive Bild-Segmentierung
KI-basierte Cloud-Segmentierungsmodelle: Interaktives Web-Interface für WissenschaftlerIn enger Kooperation mit der renommierten Universitätsklinik in Portland, Oregon, und dem Expertenteam von Quantitative Imaging, haben wir ein ambitioniertes Projekt ins Leben gerufen. Das Ziel war die Integration von fortschrittlichen KI-gestützten und klassischen Segmentierungsmodellen in einer Cloud-Umgebung, die den hohen Anforderungen des produktiven Einsatzes gerecht wird.
Dieses Vorhaben mündete in der Entwicklung eines innovativen Streamlit Web-Dokuments, gehostet auf unserer maschine learning Cloud-Plattform. Es dient als interaktives Interface für Wissenschaftler und ermöglicht es ihnen, verschiedene Algorithmen nicht nur auszuführen, sondern auch deren Ergebnisse unmittelbar zu vergleichen. Wir haben damit eine Schnittstelle geschaffen, die Forschung und Praxis auf beispiellose Weise verbindet.
Herausforderung

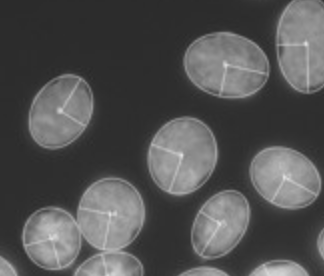
Zur Messung der Güte der Algorithmen diente ein vom Experten-Team erstellter Datensatz (Ground Truth). Das Datenmaterial umfasste fluoreszenzmikroskopische Bilder von menschlichen Gewebeproben und entsprechende Annotationen einzelner Zellen in Form von Annotations Masken.
Die klassischen Segmentierungsverfahren, die bei unserem Projekt in die Cloud gebracht werden sollten, wurden in einer vom Team entwickelten und seit 30 Jahren gepflegten internen C/C++ API zusammengefasst und als Microserive gekapselt.

Die Analysedokumente sollten präsentationsfähig gestaltet werden, um der Wisschenschaft leicht zugänglich sein. Durch Einstellen von Hyperparametern sollte es benutzerfreundlich möglich sein verschiedene Aspekte der Analyse zu beeinflussen.
Evaluierung
Unsere Arbeit begann mit der Erarbeitung von Jupyter Dokumenten (Jupyter-Notebooks), die zwecks Evaluierung in einer private-cloud unter allen Projektbeteidigten geteilt wurde. Die folgenden Punkte wurde untersucht und mit konkreten Code Beispielen untermauert.
- Scoring-Funktionen, Thema: qualitative/quantitative Aussagen über die Güte von Vorhersagen (Dice, F1, IoU, Time, CPU/GPU power),
- Hyperparameter-search, automatisierte Untersuchung optimaler Parameter bei klassischen Algorithmen,
- Model Selektion/Training, welche AI Modelle bringen SOTA Ergebnisse, genutzte ML-Frameworks, Möglichkeiten Modelle as-a-service bereit zu stellen,
- Erarbeitung von Charts und andere Visualisierungsmöglichkeiten, um optimale Einsichten zu gewinnen,
- Einbettung von c/c++ legacy Algorithmen
Die frühzeitige Erstellung eines gemeinsamen zugänglichen Dokuments schaffte Klarheit unter den weltweit verteilten Personen und stärkte das Verständniss zwischen den Experten Gruppen aus den bereichen Biotech, Informatik, Cloud-Computing und Machien-Learning.
Umsetzung
Bei der Umsetzung ist uns ein schneller Feedback-Loop wichtig. Aus der vorherigen Evaluierung identifizierten wir zwei Teil-Projekte (KiPerformanceDoc, AdvancedApi), die wir getrennt als Software-Repositories und cloud services eingerichtet haben.
- KiPerformanceDoc, eine Python-Bibliothek in der Funktionen, ML-Modelle und das finalen analyse Document als Service,
- AdvancedApi, die Einbettung der klassischen Segmentierungsverfahren (C/C++ API) als Service.
Um einem späteren produktiven Einsatz gerecht zu werden integrierten wir mittels CI/CD pipelines die services in eine gemeinsam genutzte cloud (kubernetes).
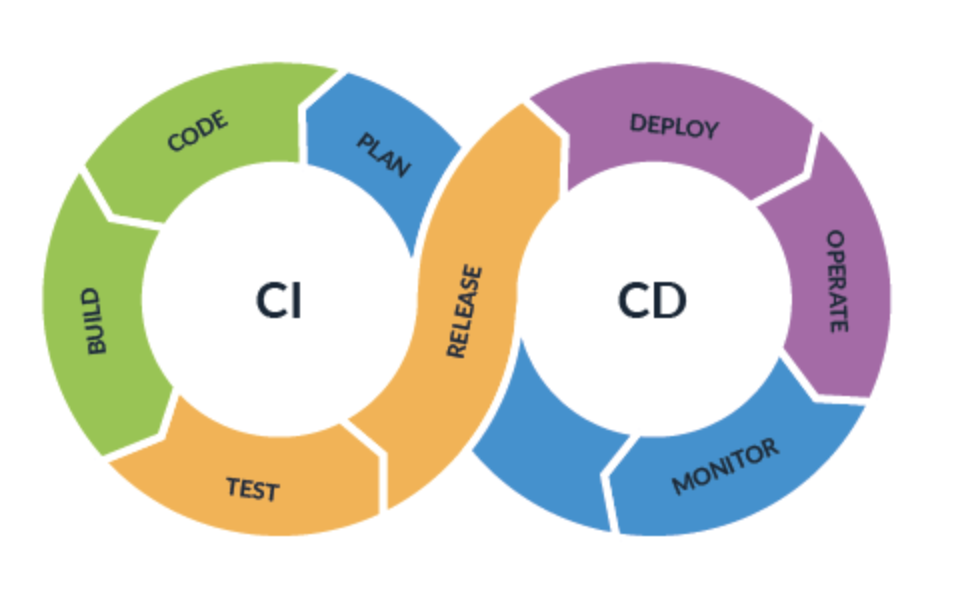
Hierbei waren die Pipelines so eingestellt, dass jeder Push in den Master-Branch nach erfolgreichem Bau und Testing zu einem Deploy der cloud geführt hat.
Ähnlich dem initialen Jupyter-Notebook ist dadurch das finale Analyse-Dokument, als Interface zu den in der Cloud verteilten Modellen/Algorithmen, von allen Beteiligten sofort einsehbar und nutzbar.
Im Unterschied zum Jupyter-Notebook der Evaluierungs-Phase entschieden wir uns bei der Umsetzung der interaktiven Dokumente für den Einsatz von Streamlit-Dokumenten, in Kombination mit parallel dazu entwickelten Python-API.
Auf diese Weise konnten wir das “Data-Science” Projekt nach Maßstäben traditioneller Softwareentwicklung behandeln, zugunsten der Nutzung einer IDE und der für CI/CD wichtigen Testbarkeit. Die Bereitstellung der Fat-Client-AdvancedApi erfolgte über Kubernetes services, während die KI-Modelle mit Hilfe von Ray-Serving in einem Sub-Cluster der selben K8s-Instanz realisiert wurde.
Ergebnisse
Interaktive-Dokumente
Jede Projekt Iteration führte zur einer ergänzenden Analyse Sektion innerhalb der geteilten online Dokumente. Angefangen von analytischen Anzeigeelementen die die Ground-Truth-Daten betreffen,
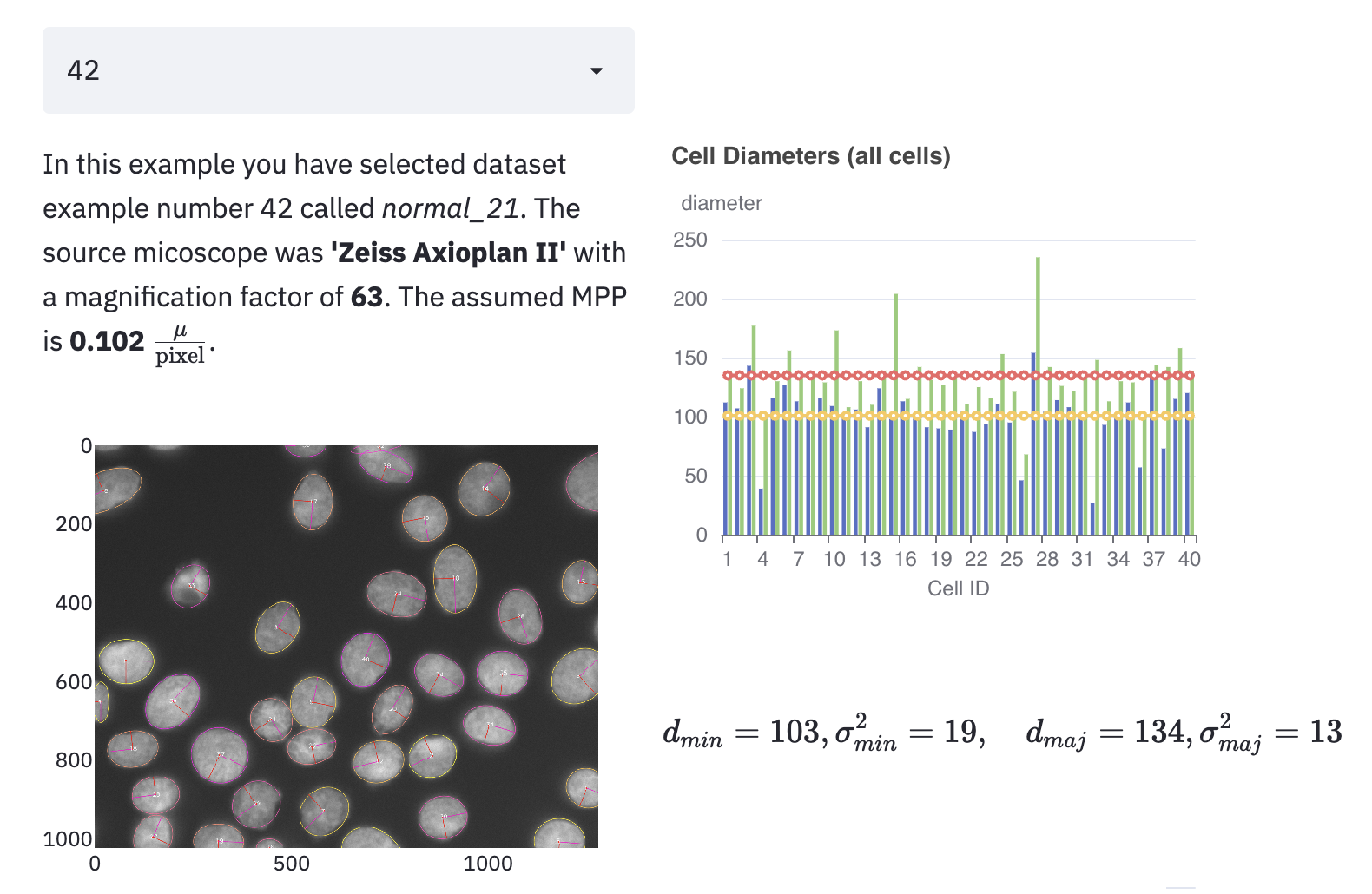
bis hin zur parametrisierten Ausführung klassischer Algorithmen (C/C++ Codebase), wo gezielt Hyperparameter gesetzt und direkt evaluiert werden können.
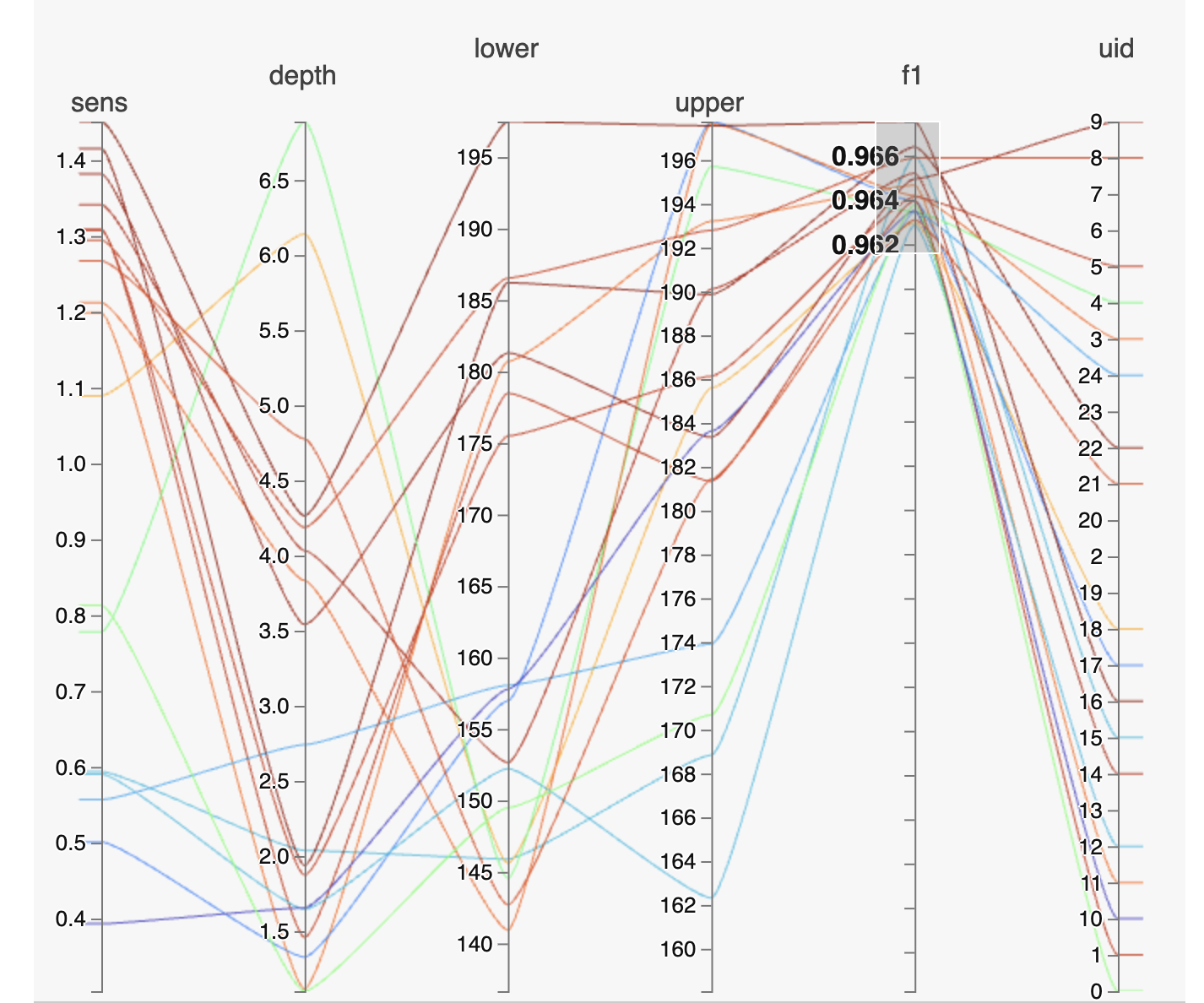
Fast Hyper-Parameter-Search
Die Transformation der C/C++ basierten CodeBase in einen Cloud-Service verhalf uns diesen nach belieben zu skalieren, was eine große Zeitersparnis bei der automatisierten Parameter-Suche (Random Grid Search) einbrachte.
Die Berechnung der klassischen Algorithmen im Bezug auf Test-Bilder und Parameter kann somit über threads eines Computers und über mehrere Computer hinweg skaliert werden. Genug Rechenleistung, um beispielsweise per random grid search verschiedene Konstellationen der multidimensionalen Parameter interaktiv zu gestalten.
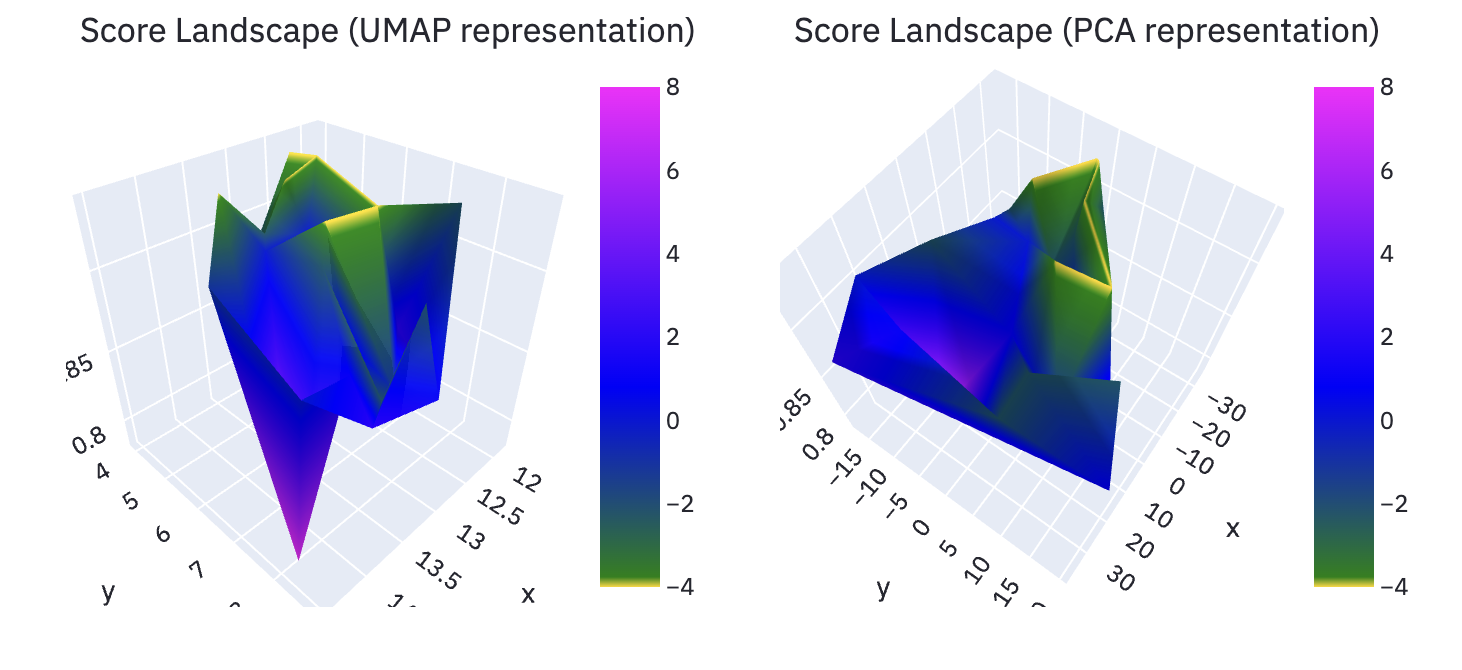
Die obigen Beispielbilder zeigen zwei Ansichten der Score-Landschaft, wie sie im finalen Analyse-Dokument genutzt werden. Mehrdimensionale Parameter und deren Score wurden hierbei auf zwei Weisen in 3D Landschaft überführt. Insbesondere durch die Darstellung mit Struktur erhaltendem Dimensions-Reduktions-Verfahren (UMAP) konnten interessante Einsichten über zusammenhängende Parameter-Bereiche gewonnen werden.
Model-Serving
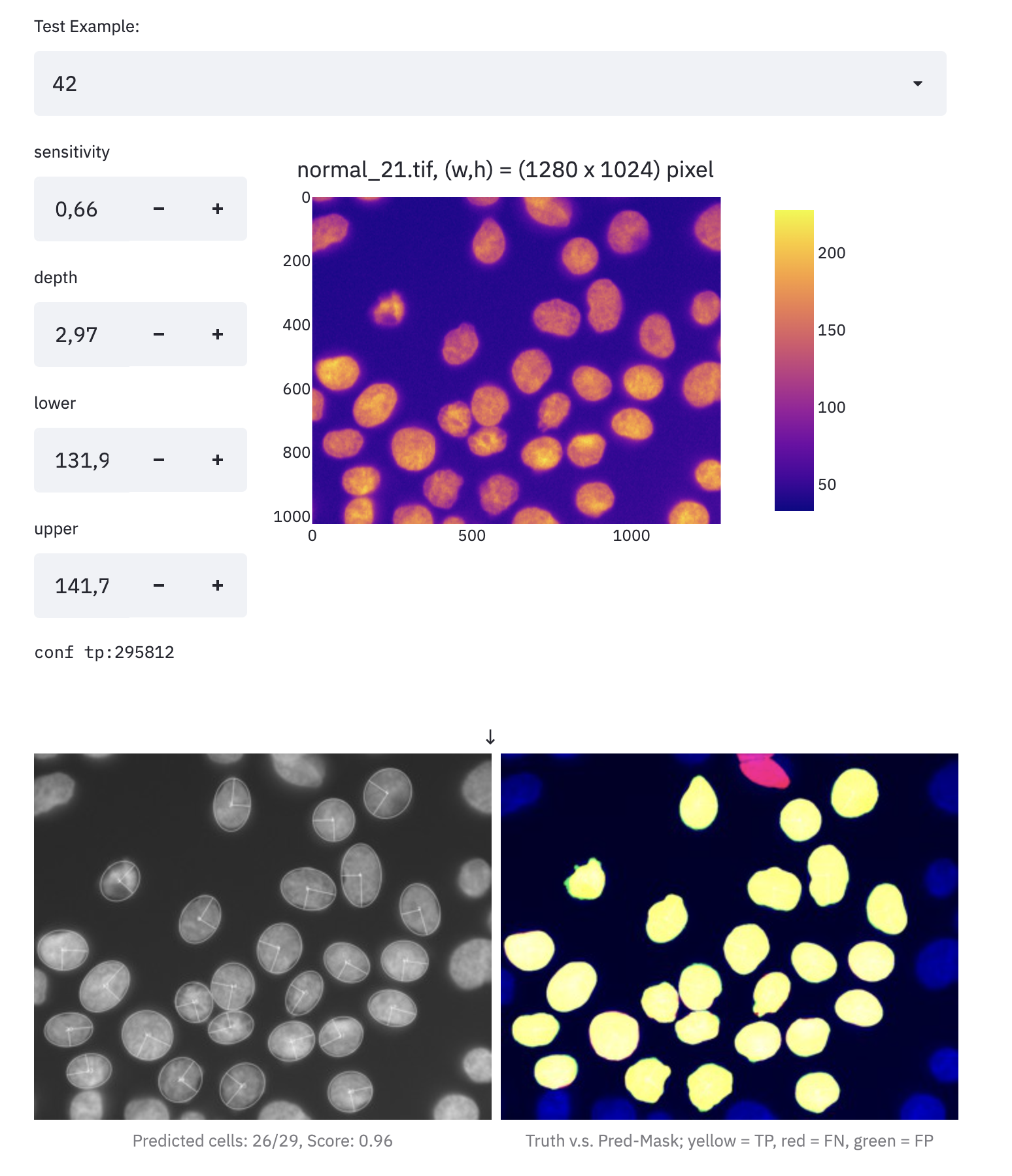
Mit Blick auf den produktiven Einsatz der Modelle in einer Wissenschaftlichen-Cloud-Anwendung, etablierten wir Ray für die Bereitstellen der KI-Modelle. Auf diese Weise entstand eine homogene “Predict” Schnittstelle, die aus den interaktiven Dokumenten genutzt werden kann um adhoc Segmentierungen zu berechnen.
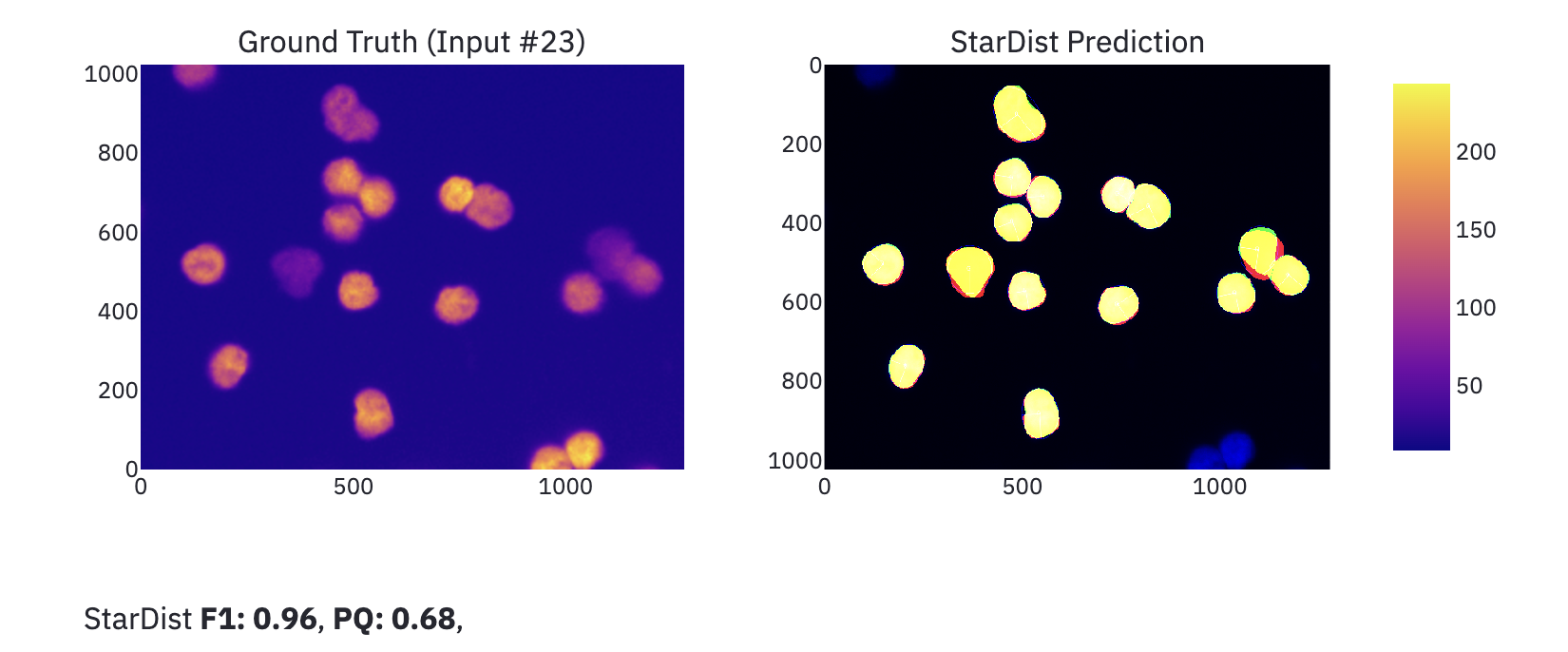
Im obigen Bild sehen wir das Ergebnis einer “adhoc” Segmentierung, die das Modell Stardist auf einem der Ground-Truth Beispiele berechnet hat.
Erkenntnisse in From von Daten
Insbesondere bei Messungen der Laufzeiten und benötigten Compute-Kapazitäten (CPU/GPU) war das produktionsnahe Setup hilfreich.
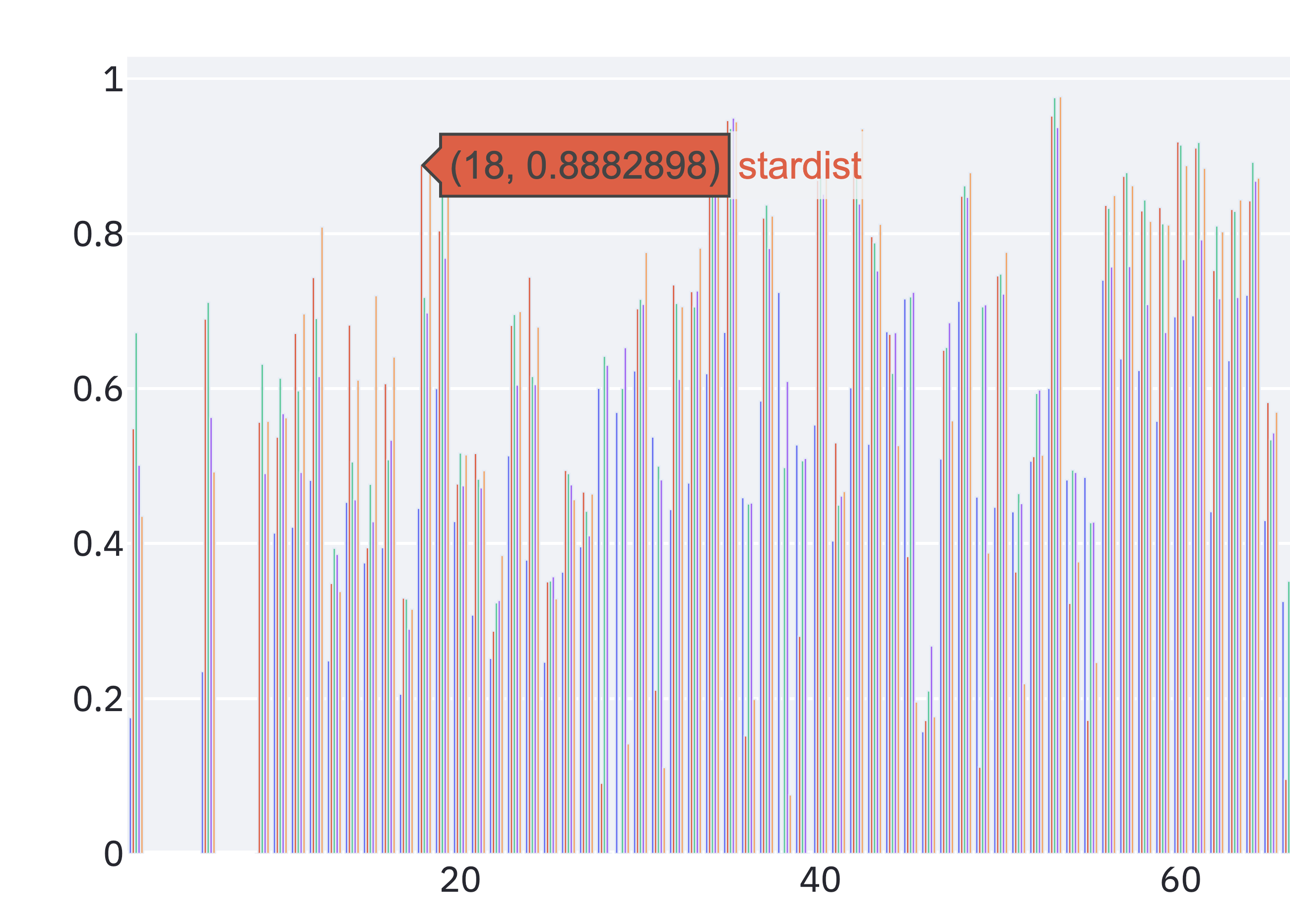
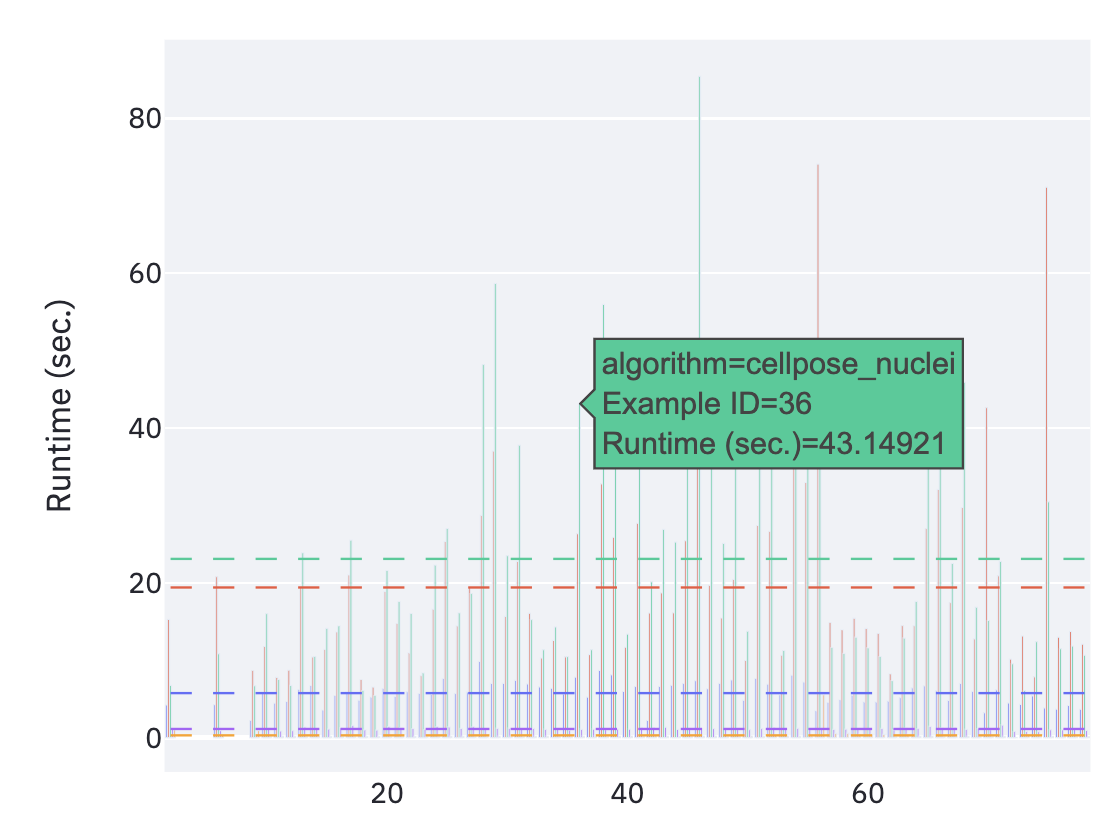
Das Projekt bildetet somit eine “self-contained” Lösung und Analyse Möglichkeit, die Reproduzierbar auch in anders provisionierten Kubernetes Clustern genutzt werden kann. Ein Wegweisendes Teilprojekt, dass uns viel Spaß gemacht hat und für das wir hiermit allen Beteiligten herzlich bedanken wollen.